Evidement mon titre est complètement con, c’est fait expres. La réponse est dans la question : pillage de contenu est forcément la bonne réponse. Et la mauvaise pratique.
Je vous raconte l’histoire
Tout commence par un post sur mon mur Facebook dont le titre m’interesse particulièrement « 9 internautes sur 10 préparent leurs achats sur Internet ». Vous pensez bien que nous sommes dans le coeur du sujet avec cette stat.
Je clique et je lis l’article
Je vois que la source est mentionnée : le Journal du Net (JDN)
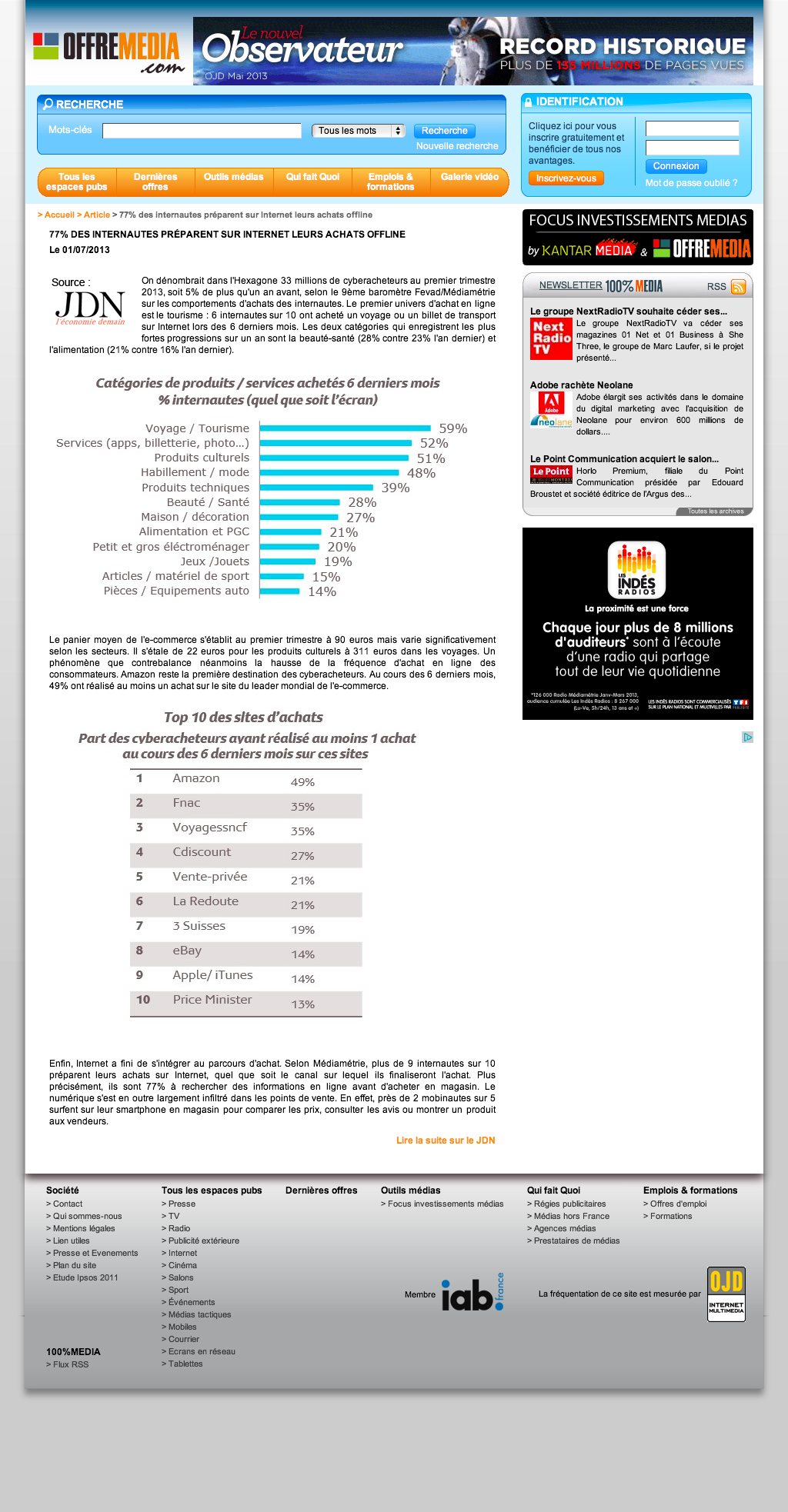
En fin d’article, un lien m’invite à lire la suite sur le JDN. Donc je clique dessus.
Et j’arrive sur l’original de l’article. Et quand je dis l’original, c’est le terme parfait car tout y est de la première à la dernière lettre

Le contenu dupliqué, c’est bien fortement déconseillé par Google ?
Piller un article aussi ouvertement par une référence comme Offre Média, c’est tout de même étonnant non ?
Prendre un bout d’article ou une capture d’écran du début du post pour ensuite renvoyer lire l’intégralité sur le site original, c’est plus respectueux et certainement mieux analysé et apprécié par Google.
N’étant pas du spécialiste SEO, si vous lecteur vous l’êtes, je vous invite à commenter l’article pour partager votre expertise et au passage améliorer ma connaissance sur le sujet.
Pingback: Duplicate content : pillage de contenu ou b&eac...
Pingback: Duplicate content : pillage de contenu ou b&eac...
Blomming parle français!
Vouz connessaiz Blomming?
Explorez un Marketplace complet d’objets uniques, des produits artisanaux et des créations de Mode indépendante … maintenant aussi en français! Jetez un oeil et bienvenue au Social Commerce.
http://www.blomming.com
Salut Bruno,
Dans tous les cas le duplicate content (DC) est pénalisant pour le site copieur car Google ne veut pas proposer le même contenu à l’internaute dans la même page de résultats.
Partant de ce principe, les filtres anti DC de Google peuvent pénaliser le site jusqu’à -95% de trafic…Google se base sur l’antériorité : le 1er document crawlé par Google est sans doute l’original.
Dans le cas présent (plagiat), le site copiant l’info doit produire de la valeur ajoutée aux internautes par rapport aux chiffres clés ou aux graphs copiés tout en le mettant à sa sauce (meta title/description, titre n…, liens), sans se tromper sur la source de l’info pour la forme 🙂
@ bientot